
I’ve been thinking for years about what is now called “linked data“: about how long the idea has been limping along, and about whether it will ever catch on the way HTML did. As we discovered over two decades ago with HTML, the simple act of linking things together has enormous value, and it’s about time we did it with data.
RDF is a potent kool-aid that true believers love to quaff deeply, but that non-believers are reluctant even to sip. I’ve considered proposing something with very simple XML (no namespaces, mixed content, or fancy underlying triples models) or even JSON, but still, those require the intervention of the digerati to produce content: there’s no app on the typical Windows or MacOS user’s desktop that can easily produce RDF, XML, or JSON (the text editor doesn’t count).
Encoding basic links in CSV
![]()
Almost anyone, on the other hand, can create CSV in a spreadsheet application like Excel, OpenOffice Calc, or Google Docs; the problem is that CSV doesn’t support links. So how about just adding a simple text-formatting convention, where links are surrounded by “{{” and “}}“? It’s still easy enough to create this kind of data in a spreadsheet application (no harder than adding a link to a Wikipedia article), and it could bring 95% of the benefit of linked data to CSV for 5% of the effort.
(Please ignore the linkification [ironically] imposed by WordPress on the fake URLs in the following examples.)
Example http://example.org/david.csv:
| id | name | country |
|---|---|---|
| 001 | David Megginson | {{http://www.example.org/canada.csv}} |
Example http://example.org/canada.csv:
| code | name_en | name_de |
|---|---|---|
| CA | Canada | Kanada |
Adding fragment identifiers and labels
We can refine that idea with a couple of additions:
- Let the fragment identifier either be a row number, or an expression to select rows with a column name=value construction.
- Allow a human-readable label separated by whitespace.
With those conventions, you don’t have to define each country record in a separate spreadsheet to allow it to be a link target.
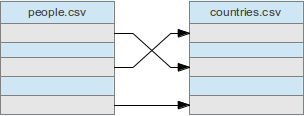
Example http://example.org/people.csv:
| id | name | country |
|---|---|---|
| 001 | David Megginson | {{http://example.org/countries.csv#code=CA Canada}} |
| 002 | Barack Obama | {{http://example.org/countries.csv#code=US United States}} |
| 003 | Angelika Merkel | {{http://example.org/countries.csv#code=DE Deutschland}} |
Example http://example.org/countries.csv:
| code | name_en | name_de |
|---|---|---|
| CA | Canada | Kanada |
| DE | Germany | Deutschland |
| US | United States of America | Vereinigte Staaten |
Update: for an alternative proposal for CSV fragment identifiers, see URI Fragment Identifiers for the text/csv Media Type.
Encoding one-to-many and many-to-one relationships
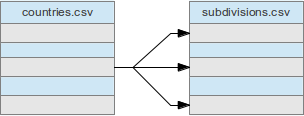
Unlike HTML, this approach also allows for one-to-many as well as many-to-one relationships, since cell values in a column don’t have to be unique.
Example http://example.org/countries.csv (take 2):
| code | name_en | name_de | subdivisions |
|---|---|---|---|
| CA | Canada | Kanada | {{http://example.org/subdivisions.csv#country_code=CA}} |
| DE | Germany | Deutschland | {{http://example.org/subdivisions.csv#country_code=DE}} |
| US | United States of America | Vereinigte Staaten | {{http://example.org/subdivisions.csv#country_code=US}} |
Example http://example.org/subdivisions.csv:
| code | country_code | country | name_en | name_de |
|---|---|---|---|---|
| CA-BC | CA | {{http://example.org/countries.csv#code=CA Canada}} | British Columbia | British Columbia |
| CA-ON | CA | {{http://example.org/countries.csv#code=CA Canada}} | Ontario | Ontario |
| DE-BY | DE | {{http://example.org/countries.csv#code=DE Deutschland}} | Bavaria | Bayern |
| DE-NW | DE | {{http://example.org/countries.csv#code=DE Deutschland}} | North Rhine-Westphalia | Nordrhein-Westfalen |
| US-CA | US | {{http://example.org/countries.csv#code=US United States}} | California | Kalifornien |
| US-TX | US | {{http://example.org/countries.csv#code=US United States}} | Texas | Texas |
Encoding internal links
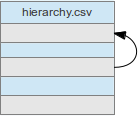
As with HTML, for internal links, just include the fragment identifier without the URL.
Example http://example.org/hierarchy.csv:
| id | boss | name | job |
|---|---|---|---|
| 001 | Barack Obama | President | |
| 010 | {{#id=001 Barack Obama}} | Hilary Clinton | Secretary of State |
Referring to rows by number
Referring to a row by number seems a lot more fragile, but you could do it like this (assuming that the header row is row 1):
Example http://example.org/subdivisions.csv (take 2):
| code | country_code | country | name_en | name_de |
|---|---|---|---|---|
| CA-BC | CA | {{http://example.org/countries.csv#2 Canada}} | British Columbia | British Columbia |
Explaining what a link means
Eventually, standards wonks get themselves tied up in knots over semantics: “sure, we know the syntax, what what does it mean?” (I know of which I speak, since I’m the one who originally pushed for the XML Infoset about a dozen years ago.) So, what does a link mean? Here’s my answer:
A link points to a more-complete and more-authoritative version of a piece of information.
That works for HTML content links as well as linked-data links. ‘Snuff.
Choosing simple defaults
Finally, it would be good to limit the amount of stupid variation, by following RFC 4180 where possible, and choosing reasonable defaults otherwise:
- The first row is always a header row, and every other row represents a data record.
- Comma (“,”) is always the field separator.
- Double quote (‘”‘) is always the quotation character.
- CRLF is always the record separator.
- UTF-8 is always the character encoding.
- Numbers, etc. are duck-typed using the default Unix locale (“C”).
- Escape literal “
{{” at the beginning of a cell by doubling it (“{{{{“).
Really, I know that some people have local sensibilities (“but we use comma for decimal places!”), but that’s a foolish reason to force everyone implementing a browser or other tool to include a gazillion if/then statements. Simple wins.
Revisions
- 2013-01-06: id ref corrected in internal linking example (thanks to Paul Tomblin).
- 2013-01-08: added link to draft-hausenblas-csv-fragment-01 (thanks to Markus Lanthaler).

Please do your best to convince me that this is a bad idea — there’s no point putting time into it unless it can stand up to early objections.
I believe the id= tag for the Hillary Clinton line is incorrect.
The syntax seems workable. The interpretation doesn’t make any sense to me. When I saw this my first thought was that it provides a mechanism for representing relational data in CSV. Nobody gets tied up in knots about what many-one relationships mean in SQL, or if they do, it’s probably a waste of time. Containment, ownership, parentage, whatever. Authority? I suppose, if you like.
I think it’s a problem that the filename is critical, but files tend to copied, moved around, renamed, versioned (get dates attached to them).
Paul: thanks — I’ve corrected the id.
Michael: also thanks — agreed about the fragility of URLs (a problem faced by all online resources, tightly- or loosely-structured), but I have not yet seen a widely-implemented solution to it. There’s no reason the URLs actually have to be file names, of course; they could be something like http://example.org/data/people (with or without content negotiation).
Does it even need the double-curly-bracket syntax? Can’t the convention be simply a value which starts with a recognizable URI prefix? (E.g http:// or file://). The descriptive text can simply be delimited by the first blank char.
And in order to make the utility of this convention fully apparent, can you talk a bit about how clients (“user-agents” in web-speak) would make use of this information? It seems to me that one reason that linked data on the web is so useful is that it corresponds to a very useful client action – that of displaying further web content, or else carrying out some action on a remote server. In order to show this isn’t just cargo-cultism some examples would be useful.
Martin: thanks for introducing two good points into the discussion.
1. Syntax — I’m still on the fence about whether an explicit syntax is necessary or not. You’re right that an unadorned URL would probably work most of the time. I just need to make sure that there aren’t rare-but-important cases that might bite us. Is it important to capture the user’s intention that this is supposed to be a link to more data (rather than just a URL)?
2. Use cases — I’m starting with two major classes of use cases: (1) humans browsing data the way they browse the web (say, to discover data to download for further analysis), and (2) machines crawling or pulling in data as needed. On the (mostly-unstructured-content/document) web, we know that crawling is useful for building search indexes. What else might crawling be useful for on a (structured-content/data) web? Hierarchical information springs to mind — for example, an index of major aid donors, each with a link to a list of their projects, and a link to the country/region where they’re talking place. In an ideal world, there would also be links to *other* donors’ projects.
Ah, good point about enhancing “crawlability”. I was thinking only of usage by humans, which is a narrower viewpoint. And (as you suggested by your mention of RDF) the bigger picture is to help link data into the “Semantic Web” (if, when, and how it ever comes to pass).
Hence the following:
1. http://dbpedia.org/page/Linked_Data — note the footer which has a link to CSV representation of the entity description
2. http://bit.ly/SboANR — why Linked Data integration into Google Spreadsheet and Excel is trivial thanks to SPARQL Protocol and the ability to hook in CSV representation of output (be it the tree based query results or entity description graphs)
3. http://www.slideshare.net/kidehen/accessing-linked-open-data-sources-via-virtuoso-odbc/6 — excerpt from presentation showing CSV basic all the way to Linked Data (presented in tabular form) .
Hi David,
The idea that all links mean the same thing (a pointer to a more-complete and more-authoritative version of a piece of information) is very limiting. Even HTML can do better than that, because the anchor text can tell you something about why the link is there (e.g. <a>earlier version of document</a>, <a>proposed revision<>
> it could bring 95% of the benefit of linked data to CSV for 5% of the effort.
95% is a very high number. The indication of link targets is only one part of linked data. Along with the ability to describe the relationships themselves, which as noted above you’ve dropped, the ability to unambiguously identify resources is key to letting anyone in the world create a link between any two resources. How do I know that “CA” in your examples doesn’t refer to California or Computer Associates? Because it has “Canada” on the same line? The country or the Richard Ford novel? If it said http://dbpedia.org/resource/Canada or http://dbpedia.org/resource/Canada_%28novel%29, I could be sure. If it was the former, I (or an automated query using a well-implemented, standardized query language) could follow links from there to http://www4.wiwiss.fu-berlin.de/factbook/resource/Canada and find CIA World Factbook data about the country. (factbook:airports_withpavedrunways_total 509, factbook:airports_withunpavedrunways_total 828. I thought you’d like those.) The fact that the CSV file has “countries” in its name won’t scale very far; “hierarchy” and “subdivisions” are both pretty vague.
RDF is more complex and lets you do more. That’s the tradeoff with just about any technology choice outside of RELAX NG vs. XSD. I don’t want to retread any arguments about whether each aspect of the complexity is worth the effort, but many, many companies and governments are getting great value from it. XLink failed, and Topic Maps failed, but RDF is churning along very nicely, and with several good reasons.
Bob
Those are good points, Bob, but whether RDF has succeeded or failed is a matter of perspective (and as with all such topics, is ultimately a futile debate). Without asserting that I have a monopoly possession of “truth” (whatever that means), I’ll just state my own contrasting point of view here.
From my perspective, RDF, at best, to a (hypothetical) successful linked-data implementation what HyperCard was to the Web. HyperCard helped people get used to the idea of hypertext and hypermedia, and it had many more features than the Web (at least for the Web’s first decade or so), but it existed only in a very constrained environment.
Of course, there were much more-powerful (though less-popular) hypermedia systems than HyperCard. I remember reading the proceeds of the annual Hypertext conferences from 1988 or 1989 before I knew about Tim B-L’s work. It was fascinating stuff, and the systems presented addressed many of the ontological and epistemelogical problems that RDF, OWL, etc. try to address for linked data. These systems had seemingly huge success inside academia during my graduate-school years from 86-92, along with some marquee non-academic implementations in corporate and other environments, but when Tim B-L introduced stupid, brain-dead, unidirectional, untyped, single-linking HTML, it took off so fast that what had previously been considered “success” for all the other hypertext systems became basically a rounding error.
I don’t expect that scale of adoption for any linked-data initiative, because the potential audience is much smaller — the potential audience for the web is anyone who can read (or now, watch videos or listen to music), while the most-optimistic potential direct audience for linked data is anyone who can use a spreadsheet (i.e. millions, not billions). But the lesson holds — start simple, and don’t try to solve problems that people don’t actually have yet. Unfortunately, I think Tim B-L forgot that lesson with the Semantic Web, and in a kind-of reverse Stockholm Syndrome, became like the hypertext academicians who were fighting and mocking him so much when he first launched HTML.
Bob, David’s idea is stronger than you think. In fact, if the features of the Hausenblas draft are adopted, his scheme is completely equivalent to RDF triples, except that there’s no way to specify b-nodes, xml:lang, or XML Schema typed literals. Each cell represents a triple: the subject is the URI of the row (using the #row:n or #where:name-value fragment identifiers), the verb is the URI of the column (using the #col:name or #col:n fragment identifiers), and the object is the content of the cell, which can be a literal or a URI. To add that power, I’d recommend switching to the Hausenblas draft wholesale, as it neatly distinguishes the different kinds of fragment identifiers that are needed, for interchange with conventional triple stores.
What is more, this scheme applies not only to CSV documents but to relational database tables, provided you have a method for a URI to specify a table within a database. If the RDBMS provides typed columns, specifically a URI type, then you don’t even need the double braces.
Are you aware of http://tools.ietf.org/html/draft-hausenblas-csv-fragment-01 ? No need to reinvent the wheel 😛
Thanks, Markus. I hadn’t read it, and was very excited about the possibility of using it, but I think it’s fundamentally flawed — it lets me select a column by header name, but does not let me select a row by a cell’s contents. Since CSV data generally represents each entity as a row, I’m assuming the most common use case will be to point to a specific row (e.g. the row where employee_id=”12345″), and the RFC doesn’t support that. I will update the blog post to include a link.
Isn’t that exactly what they call “slide-based selection” (http://tools.ietf.org/html/draft-hausenblas-csv-fragment-01#section-2.5)?
Markus is absolutely right that I misread the draft — it does allow selection of *rows* based on multiple *column* values.
The slice-based selection syntax #where:name=value is definitely better, though more verbose.
You haven’t created a system for linking CSV files. You’ve created a system for querying CSV files via RESTful operations. The only queries supported are equality comparisons, although there’s no reason that there couldn’t be more operations, aside from the fact that you’d lose some simplicity and really, you’re not trying to reinvent SQL.
You can use these queries to link data together because they’re simple text and can easily be stored via CSV.
That said, this RESTful query language you’ve built could just as easily be migrated to JSON or XML if one makes certain assumptions about the tree of those hierarchical data types. It could also query RDBMS data, or really anything.
Thanks, Remy — that’s an interesting point. Yes, fragment identifiers really are queries, though they still play an primary role in REST when you’re dealing with machine-readable data, since you’re actually identifying a target within a resource, rather than just prescrolling to a position on an HTML page.
Indeed, a link is the simplest case of a query.
Presently there a few interesting points over time in this posting however I don’t know if I view these center to heart. There can be many validity but I’ll take hold viewpoint until I discover it even more. Excellent write-up, thanks and after that we really wish for much more! Placed into FeedBurner way too
You know, I was going to point the person who wrote “CSV is a bugger for distributed, linked data” as part of a comment on Tim Bray’s latest to this page for an example of how to do it — and then I saw that it was you!
🙂